BUAA_OO_Unit3_单元总结
「BUAA OO」第三单元总结
题目说明
本次面向对象编程第三单元的主题是:「BUAA OO」第三单元总结
- 第九次作业:根据 JML 规格实现
Person类、Tag类、Network类 - 第十次作业:根据 JML 规格实现
OfficialAccount类 - 第十一次作业:根据 JML 规格实现
Message类及其3个子类
三次迭代说明
第九次作业
本次作业主要是根据JML规格实现三个接口中的所有方法,按照JML规格严格实现理论上就是正确的,所以其实要多注意细节;但是完全按照JML实现显然是不行的,哈哈tle了吧
1 | /*@ ensures \result == |
比较典型的就是这个,按照JML里面写三重循环显然是会寄的,所以要想别的方法。
经过和ai的讨论,笔者发现其实可以用动态维护的方法。也就是说,先把这个值初始化成0,然后每次addRelation或者modifyRelation或者等等时,按照要求更新值的大小。这样其实是把算法的压力分配到了加减关系上面了,而且这样做耗时短,同时也避免了冗余的计算,比如哪个坏蛋给你卡好几次。qts这你不炸了吗
除此之外,别的优化笔者倒是没怎么做。
架构图
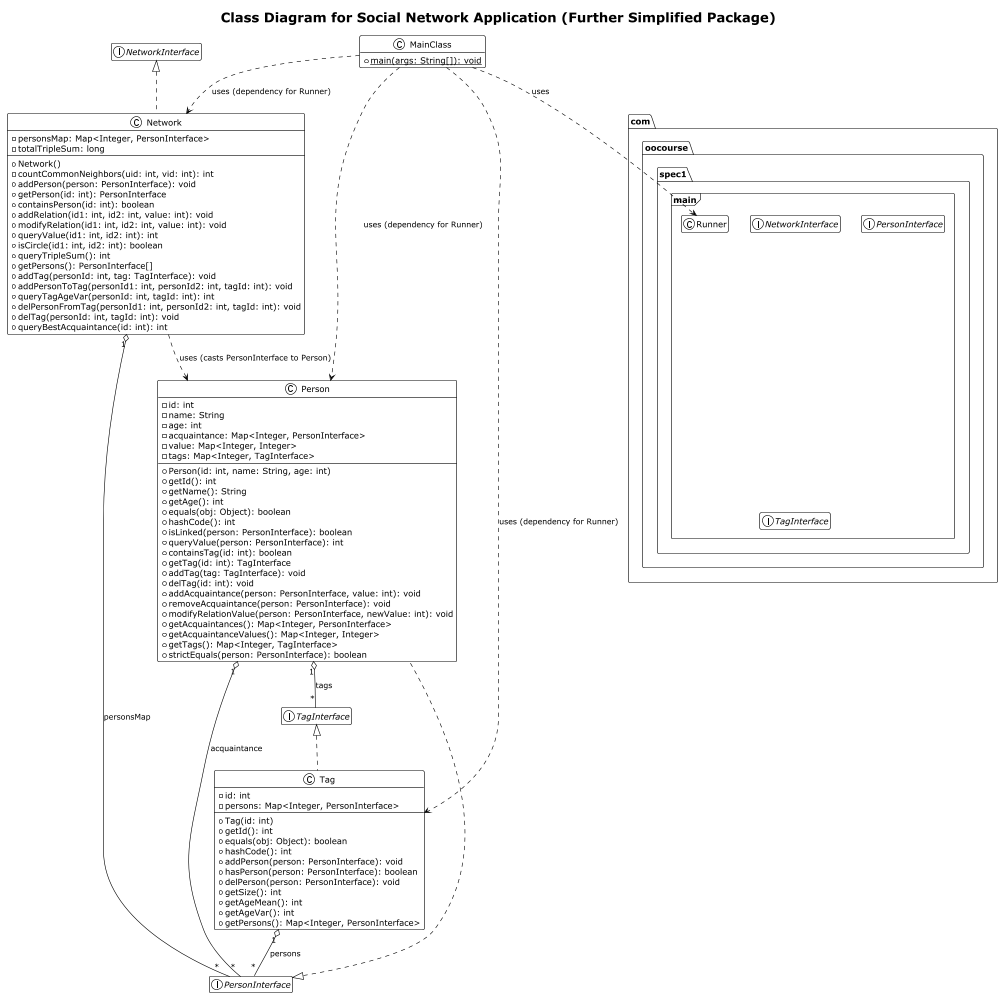
整体架构图如上所示,除了题目要求的类笔者并没有新增别的类。
代码复杂度分析
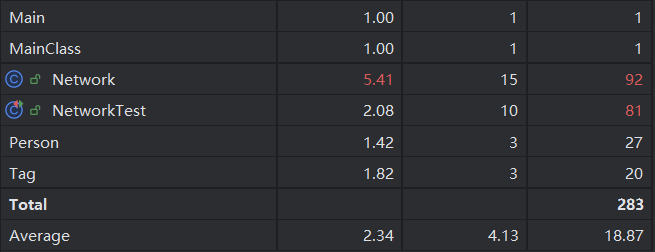
这次作业的整体复杂度不算特别高。比较高的Network类里面是在维护查询的数据。
Junit测试感悟
Junit的测试一开始有一个点一直卡着过不去,经过仔细阅读指导书后发现是pure测试的关键。一个方法是pure的,关键就在于在它调用前后,对象的属性不应当发生改变。所以,测试pure的关键就在于在调用该方法之前,将其要操作的对象深拷贝,然后和它调用后的对象进行比较。当然有个更直白的方法就是直接新建两个属性一样的实例,其中某个作为对照组来测试,管它什么拷贝
第十次作业
本次作业新增了一个OfficialAccount类,另外,原先的类里面也有一些新的迭代内容。
本次强测tle了好几个点,五一玩的太嗨了,没有做细致的优化。比较卡时间的就是这个方法
1 | /*@ public normal_behavior |
这个其实跟前一次作业还是一样的,做好动态规划就好了,并不是什么复杂的问题。当然这个要做动态规划的话还要注意一些深层次的细节。笔者在完成了动态规划之后还有一些细节上的bug,处理了很久。在第十一次作业的自测过程中,与这个方法有关还出了一个非常细小的bug,这个之后再说。
在互测过程中,笔者也针对性的设计了一些和qtvs有关的测试数据,成功hack到了房友。
另外,在进行了上述优化之后,所有强测点,笔者最慢的在本地用profiler分析,也能压缩到1600ms以内,但是评测机跑下来就是tle,真该加强一下这个烂评测机了。所以笔者在仔细考虑之后,将这个方法
1 | /*@ public normal_behavior |
由常规的BFS算法,即广度优先算法,优化成了双向BFS算法。至此之后,最慢的点也能在500ms就能跑完了。
双向 bfs,或说图的双向搜索算法,是对于广度优先搜索算法的一种改进。bfs 从起点开始由浅入深地遍历,直到找到终点;而双向 bfs 则从起点与终点同时开始遍历,直到遍历的区域相交(说明找到了最短路径)。
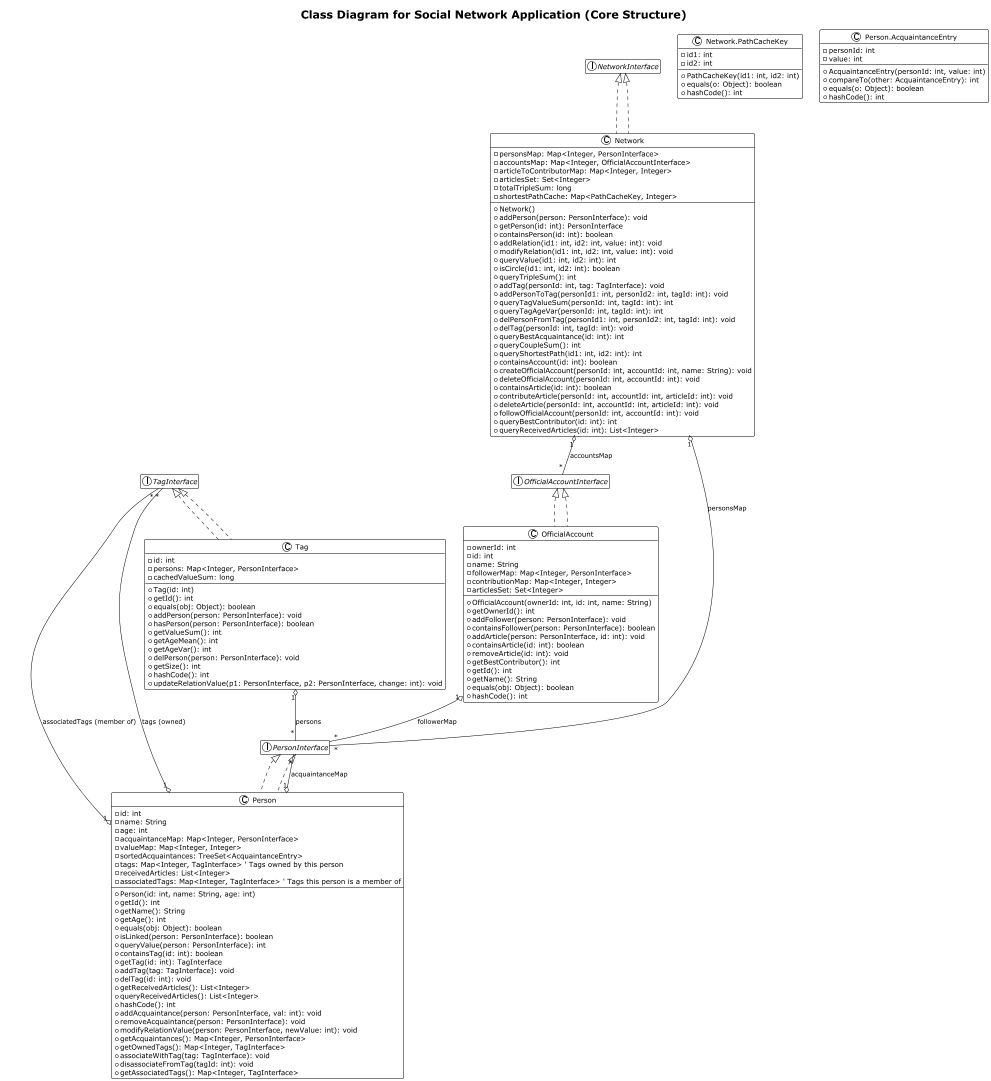
架构图
代码复杂度分析
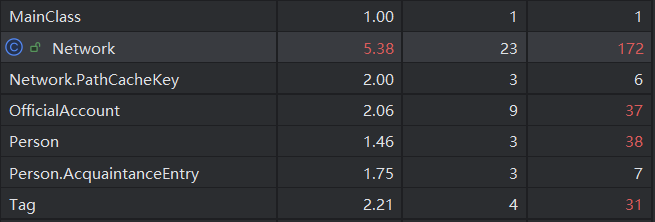
本次作业复杂度整体就有点高了,主要集中在Network类,因为其中包含了queryShortestPath方法和modifyRelation方法。
第十一次作业
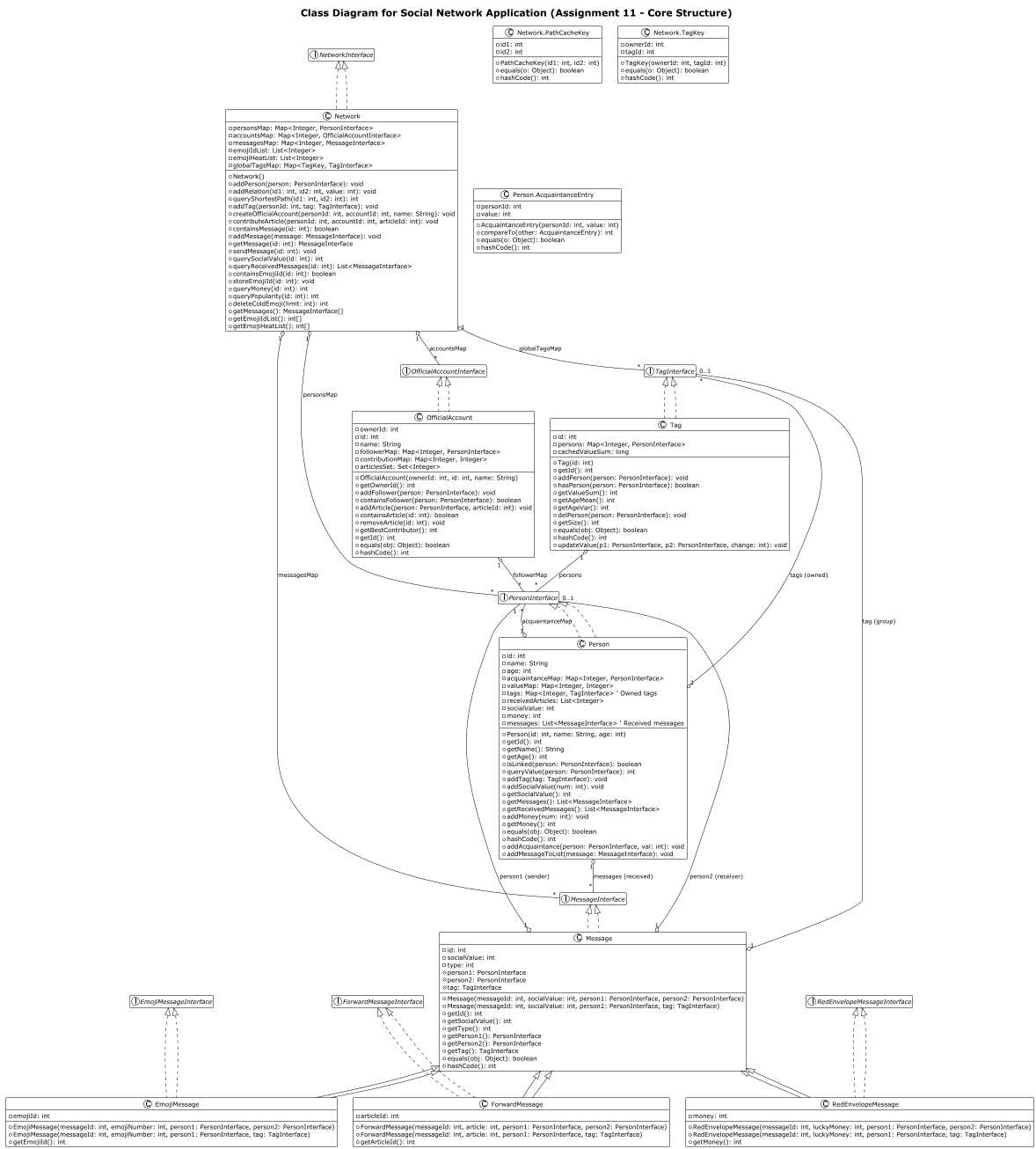
这次作业主要新增了Message类以及它的三个子类。
本次作业值得注意的点倒是不算多,笔者个人认为只有一个:在第十一次作业里面,sendMessage的加入,可能使得相同的文章可能会被转发到一个人的容器中。在删除的时候,需要将所有该id的文章都删掉。
另外,在自行测试的时候,笔者发现了一个非常隐蔽的bug。因为Tag是允许id相同但是实例不同的。也就是说,两个person,他们各自拥有一个tag,这两个tag显然实例是不同的,但是他们可以拥有相同的id。在笔者的实现中,当发生了modifyRelation的时候,需要找到同时包含这两个person的tag,因此笔者采用了一个HashMap来记录这个人所在的tag,而key便是使用了tag的id。然而,一个人可能同时处于id相同的不同tag里面,HashMap的key一定是唯一的,所以用HashMap来记录必然是错误的。
笔者在与小伙伴们讨论之后,采用了这样一种方式:
1 | private static class TagKey { |
采用这样的一种数据结构来记录tag的“唯一id”,这样就确保了key是唯一的
架构图
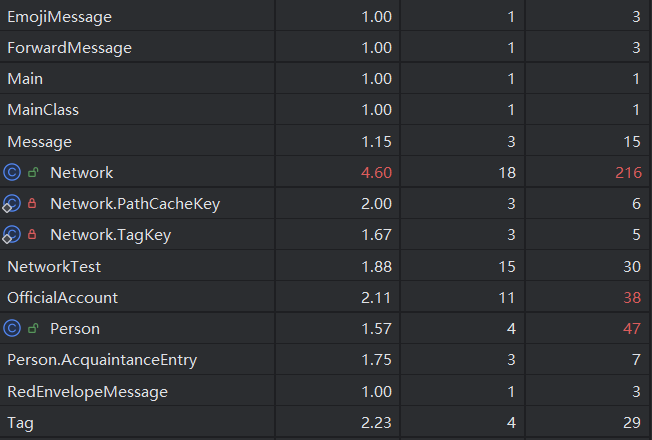
代码复杂度分析
测试过程
测试思想
黑盒测试
黑盒测试,把程序看作一个不能打开的黑盒子,在完全不考虑程序内部结构和内部特性的情况下,在程序接口进行测试。黑盒测试着眼于程序外部结构,不考虑内部逻辑结构,主要针对软件界面和软件功能进行测试。
——百度百科,黑盒测试
评测机其实就是一种黑盒测试,它只关心程序是否能产生正确的输出,不关心程序内部是如何运作的。
白盒测试
白盒测试是一种测试用例设计方法,盒子指的是被测试的软件,白盒指的是盒子是可视的,即清楚盒子内部的东西以及里面是如何运作的。“白盒”法全面了解程序内部逻辑结构、对所有逻辑路径进行测试。
——百度百科,白盒测试
本单元要求学生设计的 Junit 测试便是一种白盒测试,它要求被测方法的行为完全符合规格说明,不能产生越界的行为。
测试方法
单元测试
单元测试是针对程序模块来进行正确性检验的测试工作。在过程化编程中,一个单元就是单个程序、函数、过程等;对于面向对象编程,最小单元就是方法。单元测试的目标是隔离程序部件并证明这些单个部件是正确的。
本单元的Junit就是一种单元测试。
功能测试
功能测试就是对产品的各功能进行验证,根据功能测试用例,逐项测试,检查产品是否达到用户要求的功能。功能测试也叫数据驱动测试,只需考虑需要测试的各个功能,不需要考虑整个软件的内部结构及代码。
——百度百科,功能测试
功能测试其实就是一种黑盒测试。
集成测试
集成测试,即对程序模块采用一次性或增值方式组装起来,对系统的接口进行正确性检验的测试工作。整合测试一般在单元测试之后、系统测试之前进行。实践表明,有时模块虽然可以单独工作,但是并不能保证组装起来也可以同时工作。该测试,可以由程序员或是软件品保工程师进行。
——Wikipedia,集成测试
压力测试
压力测试,顾名思义就是针对特定的系统、组件、程序等,采用超过正常使用条件下的情况进行运转,确认在极限状态下,程序是否能够正常运转。
到目前笔者还没用使用过这种测试方式,但似乎航空航天设计经常会使用这种测试方法(确认系统在什么条件下会损坏,以及安全使用条件)。
回归测试
回归测试是指修改了旧代码后,重新进行测试以确认修改没有引入新的错误或导致其他代码产生错误。自动回归测试将大幅降低系统测试、维护升级等阶段的成本。
——百度百科,回归测试
数据构造
本次笔者只写了一个简易的数据生成器,规范了生成数据的合法性以后,手动添加了一些条件来增加数据的强度。生成数据时应当优先考虑JML规格中描述的每一个方法的behavior。由于时间有限,并没有刻意去构造足够强大的测试数据。因此笔者的数据生成器主要在本地测试时发挥了作用,在互测阶段成功刀中了几个人。
如何引导大模型在不同场景下完成复杂任务
现在的大模型整体可用性非常高,一般来讲不用刻意去多步引导。笔者尝试过直接使用大模型完成第十一次作业,其完成的比较完善,性能方面有所欠缺,代码风格惨不忍睹,但其他方面确实很优异,笔者只进行了细节上的优化与维护和性能上的改善。
契约式设计
契约式设计是一种设计计算机软件的方法。这种方法要求软件设计者为软件组件定义正式的,精确的并且可验证的接口。
契约式设计的核心在于分离规格设计与代码实现。设计者通过需求来设计与撰写每个方法的规格,程序员通过规格来实现代码。这种设计思想可以有效减少代码中的bug数量,提高代码的可靠性与可维护性;但由于契约式设计需要为每个类书写详细的契约(契约长度往往会超过代码本身的长度),这种设计方式会显著地降低开发的速度。因此在实际应用中往往在设计代码的核心模块中使用,以保证核心模块的正确性。
JML是一门非常冷门的规格建模语言,课程组并未让学生们完成由需求设计规格这一层次,而是将三次迭代的重点放在了由规格实现代码。基于规格的层次化设计有两个层次,一是根据需求设计规格,二是根据规格实现代码。课程组将绝大部分重心都放到了后者之上,笔者认为不是很合理。可以尝试让同学们自己编写JML规格。
Junit测试
Junit测试是由规格设计引来的测试,旨在验证代码是否符合规格说明书。想要进行Junit测试,前提是拥有一个完全正确的规格,否则Junit测试完全是一纸空谈。
数据生成
本次Junit测试我并没有考虑随机数据构造,只是选择了15-30个有特色的数据点进行测试充分覆盖JML规格中各个behavior的requires和ensures。
断言
深度检査JML规格中not_assigned的属性,保存一份方法执行前的深拷贝,保证各个属性未发生变化。逐行检查requires和ensures。
心得体会
本单元的学习,笔者大致学习到规格化设计的步骤,体会到规格化设计的优点。本单元对于Junit的学习,让我理解了Junit的使用方法与其存在的意义。


