BUAA_OS_Lab1_实验报告
思考题
Thinking 1.1
在阅读 附录中的编译链接详解 以及本章内容后,尝试分别使用实验环境中
的原生 x86 工具链(gcc、ld、readelf、objdump 等)和 MIPS 交叉编译工具链(带有
mips-linux-gnu- 前缀,如 mips-linux-gnu-gcc、mips-linux-gnu-ld),重复其中的编
译和解析过程,观察相应的结果,并解释其中向 objdump 传入的参数的含义。
指导书中提到的objdump指令为
1 | objdump -DS 要反汇编的目标文件名 > 导出文本文件名 |
其中:
-D表示:反汇编(Disassemble)那些预计包含指令的所有节区。-S表示:在反汇编输出中,尽可能地将源代码(如果编译时包含了调试信息,通常是使用 gcc -g 编译)与汇编代码交错显示。这对于理解某段汇编代码对应哪行 C/C++ 源代码非常有帮助。通常需要与-d或-D一起使用。-d表示:反汇编那些预计包含指令的代码节区。
首先,编写一个简单的程序helloworld.c,如下
1 |
|
执行mips-linux-gnu-gcc -E helloworld.c > temp命令,只进行预处理,不进行编译和操作,找到文件末尾的位置,如图所示
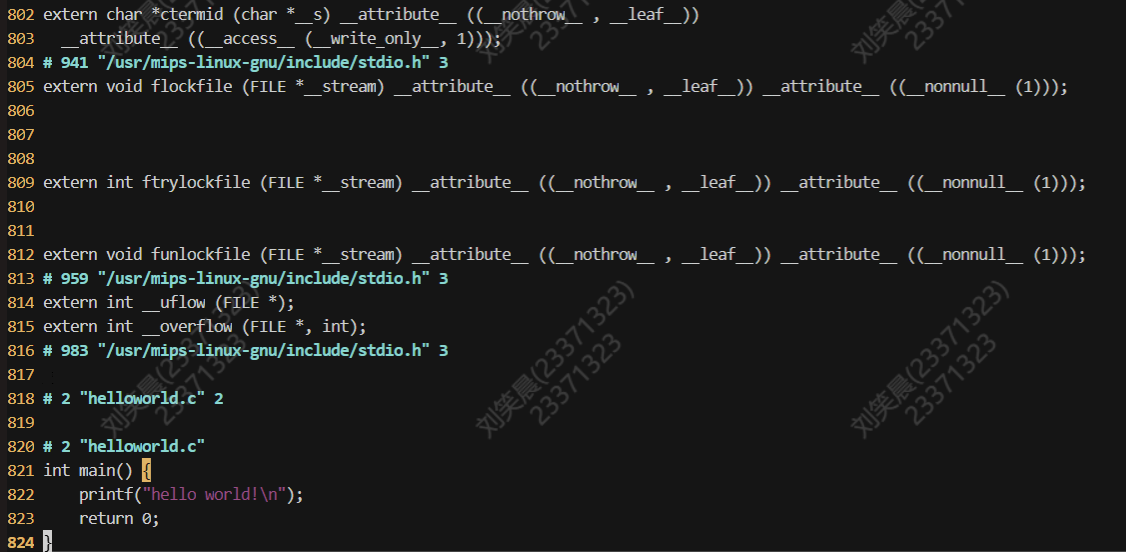
预处理只不过是将头文件展开,替换成相应的代码,并没有任何编译和链接
依次执行下面两个命令
1 | mips-linux-gnu-gcc -c helloworld.c |
这两个命令分别是针对MIPS架构的交叉编译和反汇编操作
第一个命令是使用交叉编译器mips-linux-gun-gcc对helloworld.c文件进行编译,最终会生成目标文件helloworld.o
第二个命令是使用mips-linux-gnu-objdump工具对目标文件helloworld.o进行反汇编,并将结果输出到temp中
最终结果如图
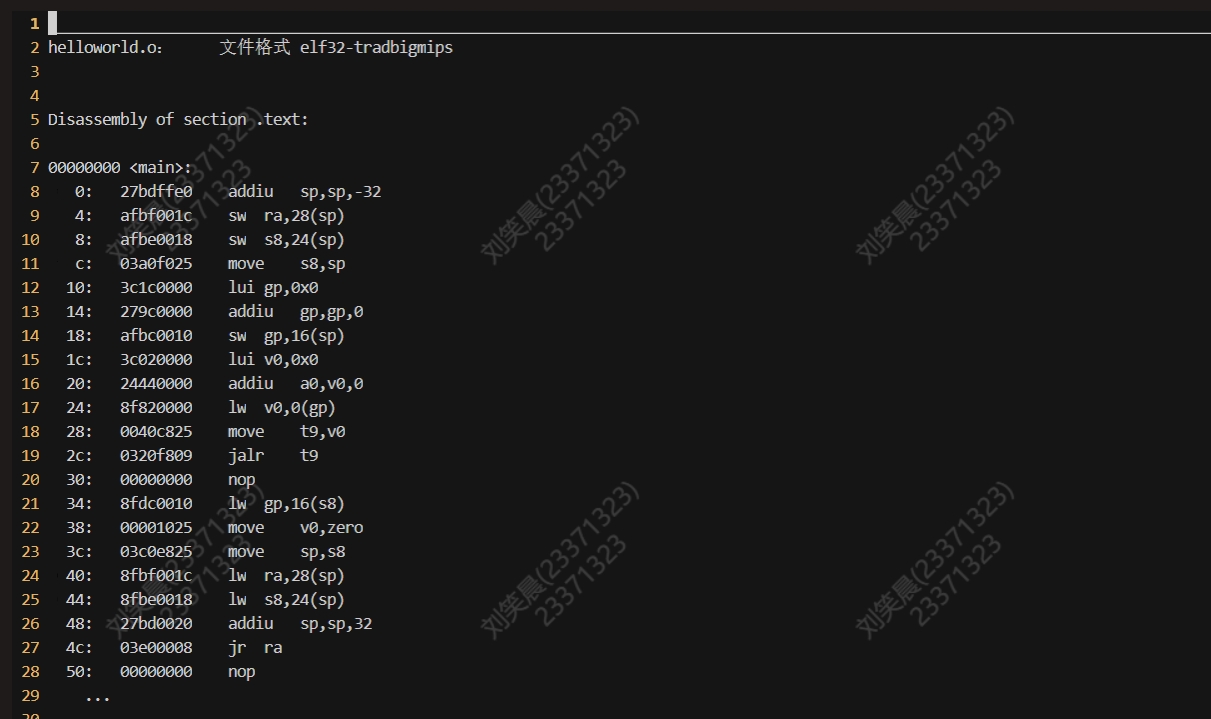
我们发现反汇编的结果中包含了源代码中定义的变量和函数
再执行下面两个命令
1 | mips-linux-gnu-gcc -o helloworld helloworld.c |
这两个命令是用于编译和反汇编 MIPS 架构程序的操作
第一个命令是使用交叉编译器mips-linux-gun-gcc对helloworld.c文件进行编译,生成可执行文件helloworld
第二个命令是使用mips-linux-gnu-objdump工具对名为helloworld的可执行文件进行反汇编,并将反汇编结果输出到temp中
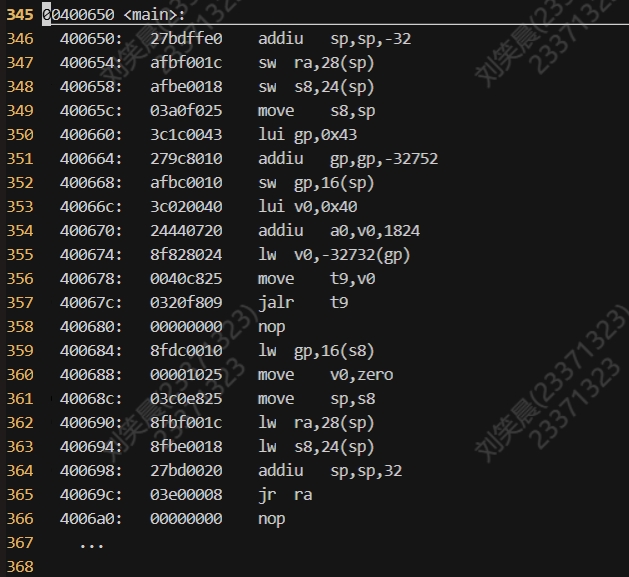
我们发现main函数被分配到了00400650的地址上
查阅相关资料后,我们知道:
如果只编译不链接
- 生成目标文件(.o 文件),包含了编译后的机器代码和符号表信息,但还没有进行符号解析和地址重定位
- 如果涉及多个源文件,每个源文件都会生成对应的目标文件,但它们并未合并在一起
编译并连接
- 将各个目标文件连接在一起,解析符号引用,填充地址空间,并生成最终的可执行文件
- 在链接过程中,可能还会包含库文件、共享对象等,以及进行符号解析和地址重定位
Thinking 1.2
思考下述问题:
- 尝试使用我们编写的 readelf 程序,解析之前在 target 目录下生成的内核 ELF 文
件。
- 也许你会发现我们编写的 readelf 程序是不能解析 readelf 文件本身的,而我们刚
才介绍的系统工具 readelf 则可以解析,这是为什么呢?(提示:尝试使用 readelf
-h,并阅读 tools/readelf 目录下的 Makefile,观察 readelf 与 hello 的不同)
运行./tools/readelf/readelf ./target/mos指令,得到
1 | 0:0x0 |
我们得到了一系列的地址信息。但当我们用readelf程序去解析自身,却发现无法成功。这是因为我们编写的 readelf 程序仅支持解析32位 ELF 文件,而程序自身实际上是一个64位的 ELF 文件。
我们用readelf -h命令分别对hello和readelf文件进行头部信息解析。hello文件结果显示为ELF32,而readelf文件则显示为ELF64
实验难点
本次实验主要分为内核初始化阶段的底层配置和用户功能模块开发两个部分。在系统启动环节中,我们重点进行了内核地址空间的重新规划与启动流程的汇编级实现。这需要结合工程中的多维度技术文档,特别是通过解析内存映射示意图来修正链接脚本(kernel.lds)中的段地址参数,同时需要深入理解平台相关的宏定义体系,才能准确完成start.S中关键寄存器的初始化配置。虽然这部分基础代码量不大,但涉及到底层硬件与编译工具链的深度协同,需要建立完整的地址空间映射认知
在功能开发层面,实验包含两个特色模块的实现。首先是类readelf工具的核心功能仿真,虽然需要补全的代码片段有限,但整个工程架构涉及ELF文件格式解析的完整处理流程。为此必须仔细研读工程中预定义的节头表、程序头表等数据结构,并理解各字段在二进制解析过程中的动态填充机制。其次是内核级日志输出系统printk的完善,该任务虽然只需在现有框架内补充少量格式化处理逻辑,但要真正掌握其设计精髓,需要通盘分析可变参数处理机制、字符缓冲管理策略以及终端驱动接口的调用层级。特别值得注意的是,三个关联文件之间的数据流向和函数调用关系构成了完整的输出处理链条,这对理解操作系统内核的模块化设计思想具有重要价值
实验体会
这次实验,我们整体的工作量并不是很大,难度也不高。但是比较重要的一点是我们要仔细阅读给出的代码,把握细节。把架构理清楚,代码的编写和补全就很轻松了。在补全代码的同时,我也学到了很多更有趣的c代码编写方式,也算是给我带来了更高端的代码编写细则


